Part One · Engineering
Cat Boarding
Web App
Web App
Zero to Production, Built End-to-End with Claude Code
 GitHub Copilot
GitHub Copilot Cursor
Cursor Gemini CLI
Gemini CLI Claude Code ✦
Claude Code ✦ OpenClaw
OpenClaw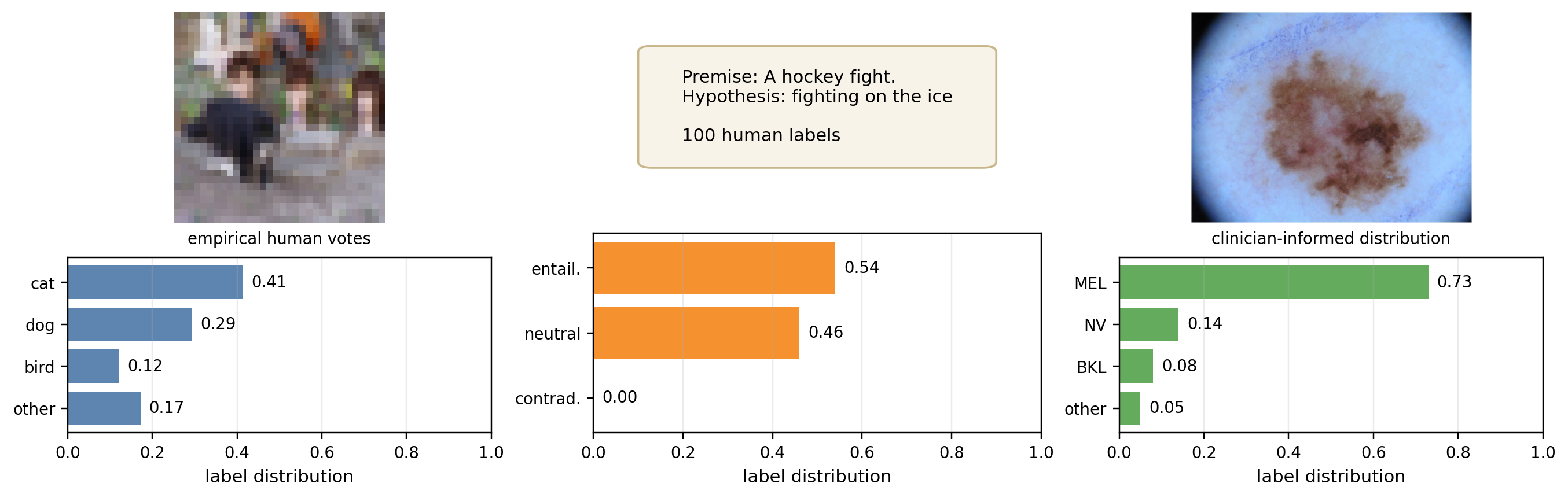
Conformal Prediction × Annotation Ambiguity
When ground truth is inherently ambiguous (annotators disagree), do CP's coverage guarantees still hold?
Calibration in This Setting Hasn't Been Done
Annotation ambiguity + calibration — even “how to evaluate” has no consensus
Pivot → CalibrationAGT
Calibration in this setting is equally worth systematic study.
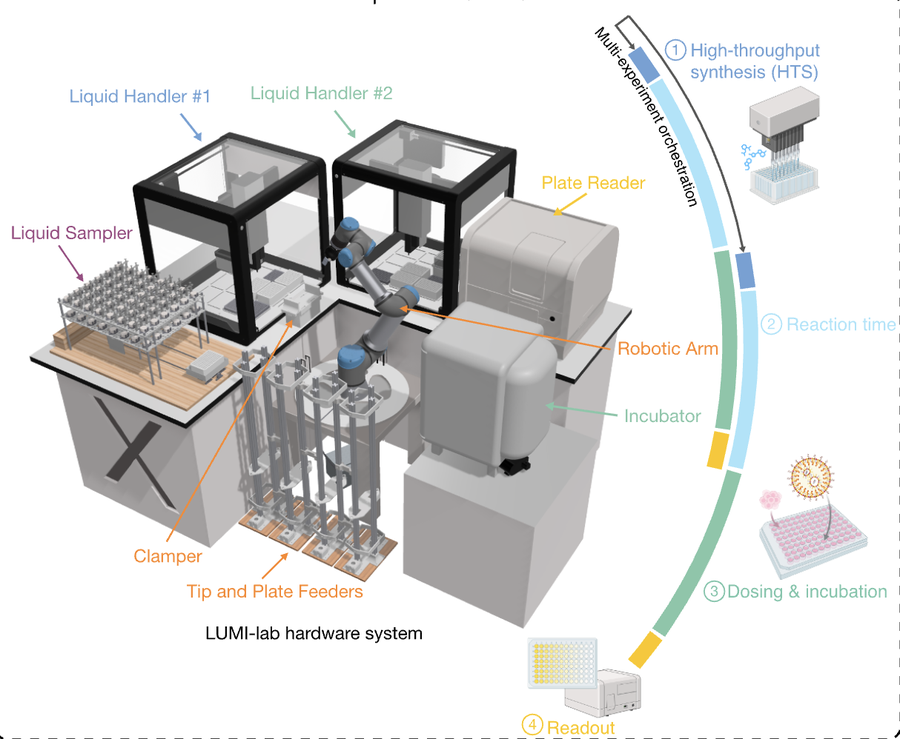
Figure 1: LUMI-lab overview — foundation model + active learning + robotic lab → 1,700 LNPs → 20.3% lung gene editing in vivo
Work is about being accountable for outcomes负责
不是对过程负责,不是对代码行数负责,不是对"我自己写的"负责

"Vibe coding — fully give in to the vibes, embrace exponentials, and forget that the code even exists."
X · Feb 2025 → now: "agentic engineering"

"We may see the first AI agents join the workforce and materially change the output of companies."
Blog · Jan 2025

"AI could soon compress decades of scientific progress into just a few years."
Machines of Loving Grace · Oct 2024
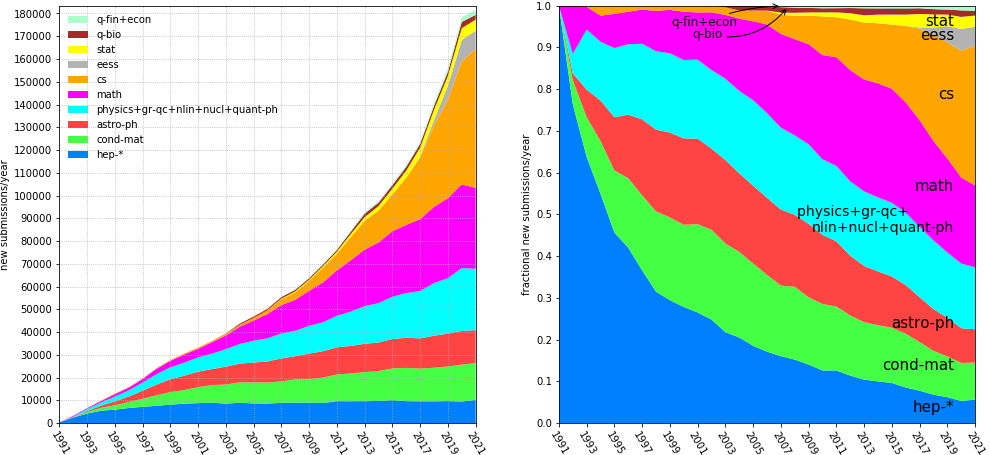
Agent lets anyone churn out papers fast — hundreds per day on arxiv, reviewers already can't keep up
arXiv annual submissions · arxiv.org/stats (2025: exceeded 28,000/month)
Stanford · Oct 2025 · agents4science.stanford.edu
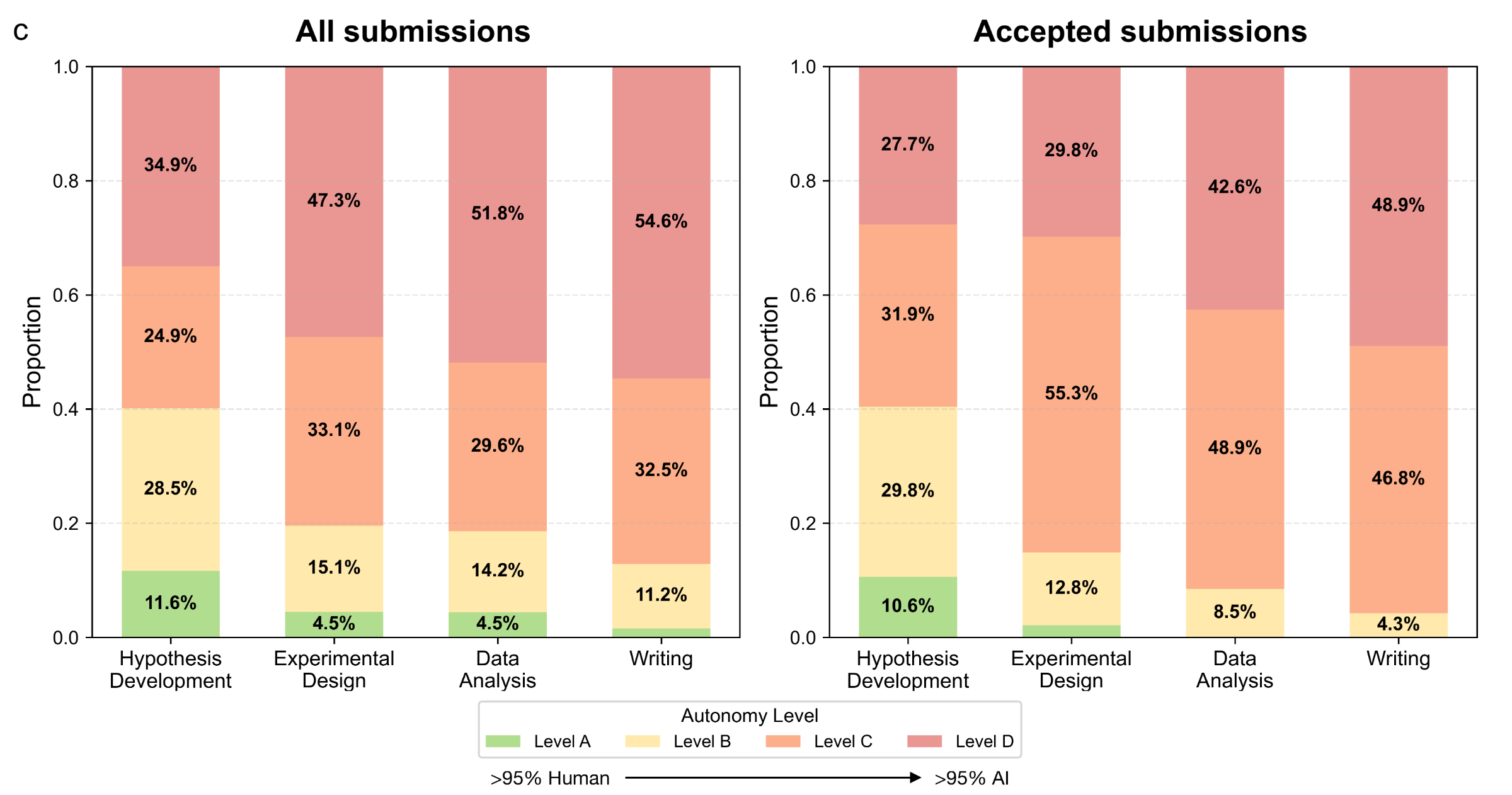
AI can generate papers — but asking the right question still needs humans仍然需要人
Ref: Hung-yi Lee · AI Agent (3/3) · NTU 2026
Andrew Hall (Stanford) · 「100x Research Assistant」
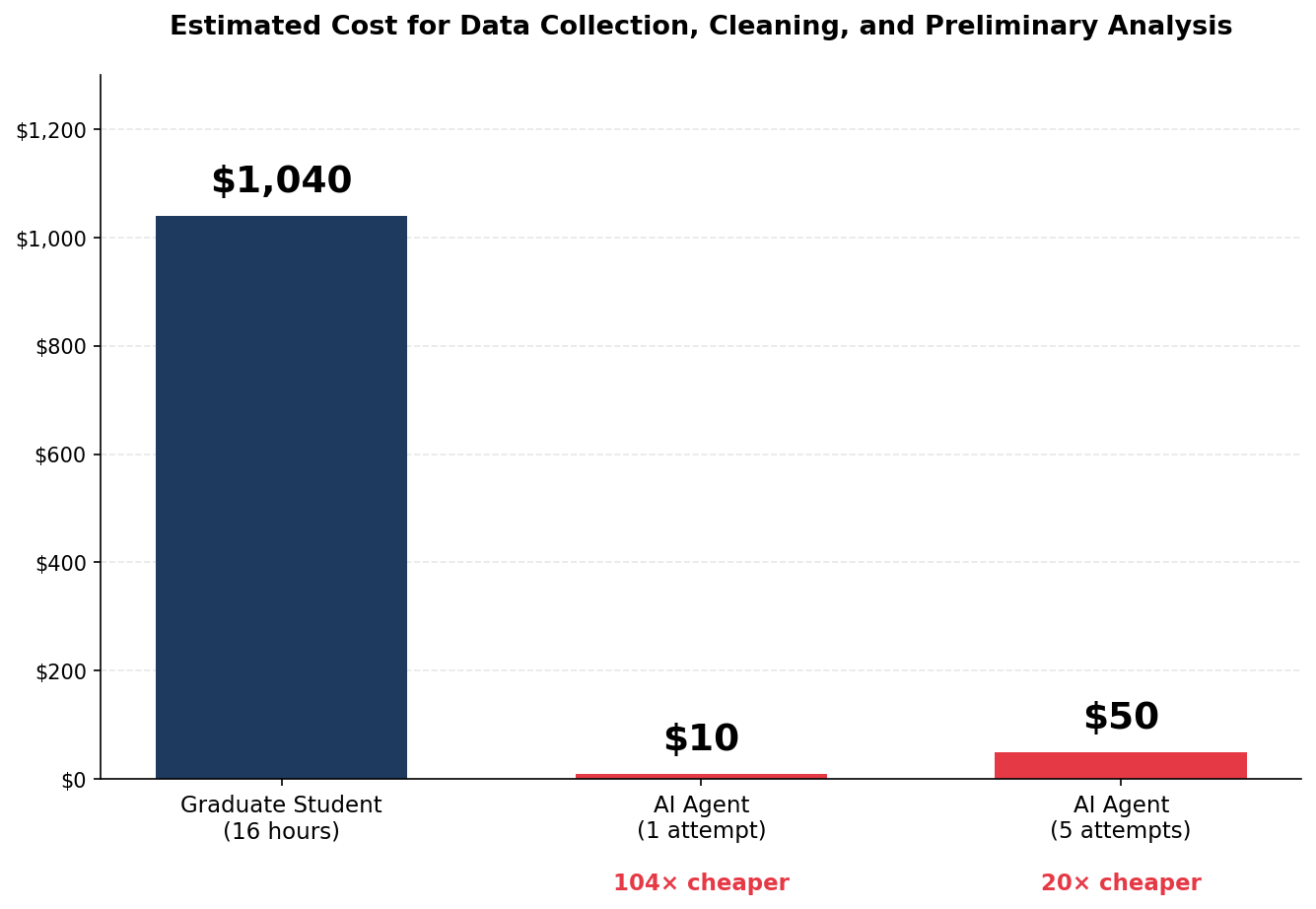
PhD student: 16h / $1,040 vs Claude Code: 1h / $10 (104× cheaper)
But: humans haven't been replaced
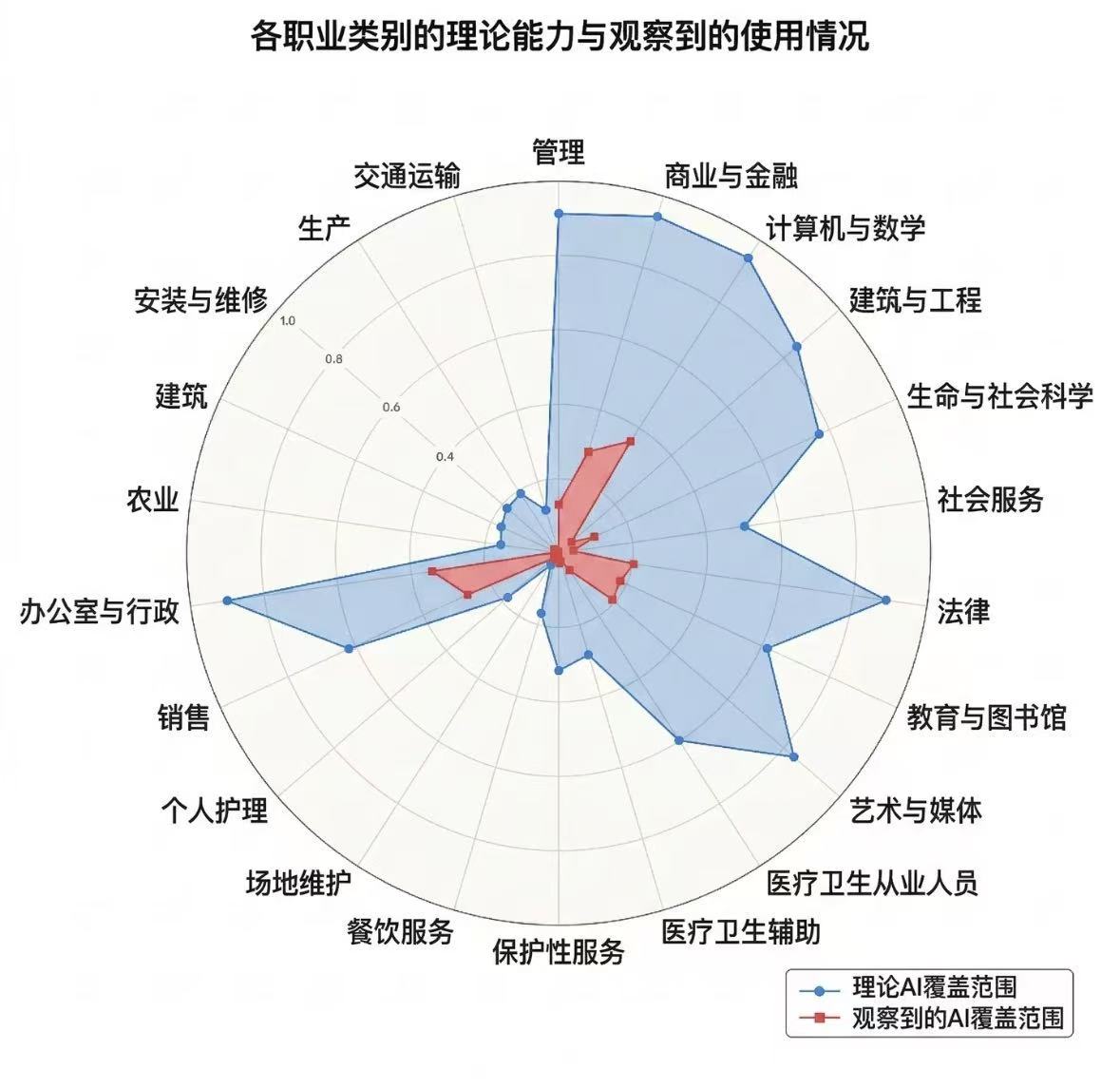
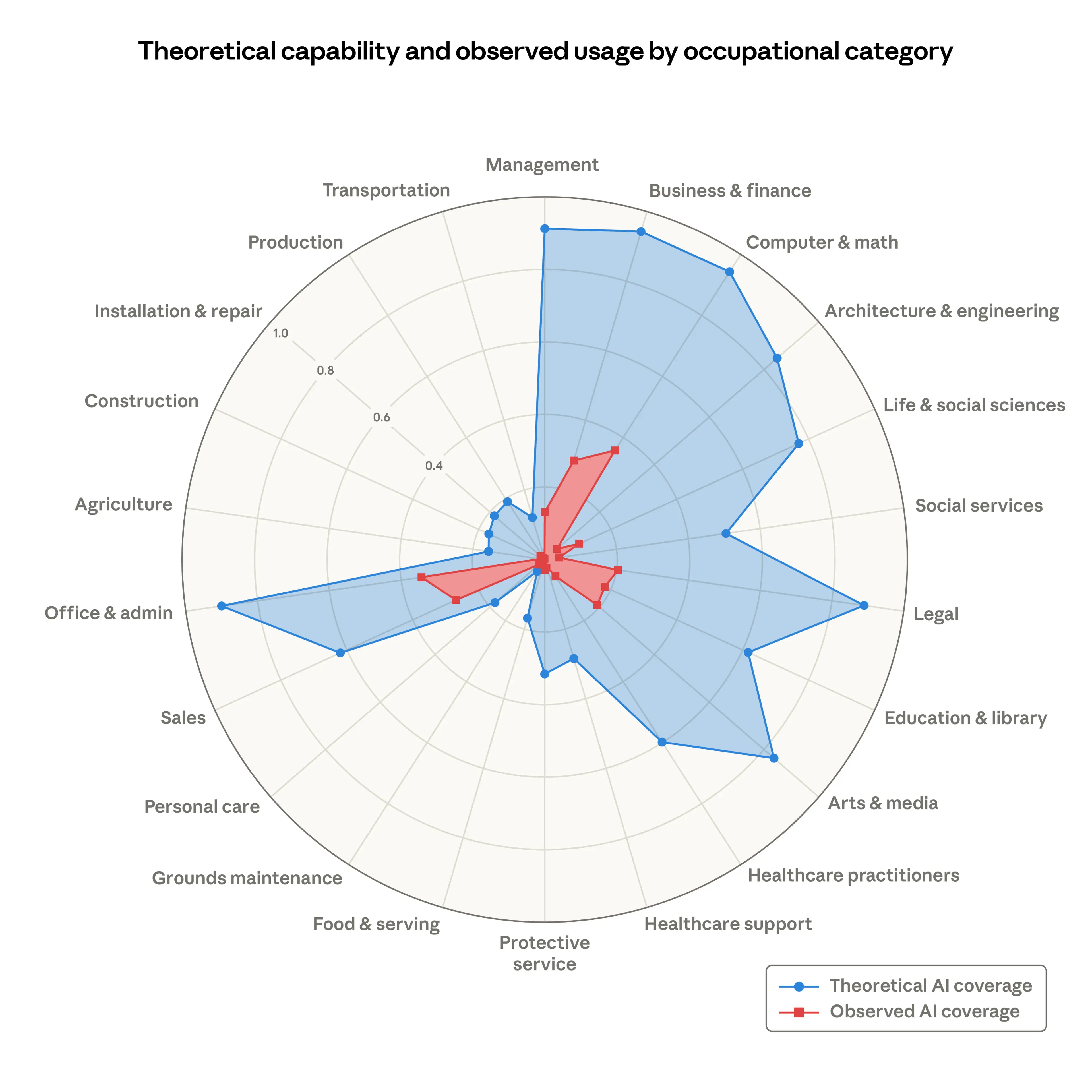
Real-time GPU monitoring across all lab servers —
see which cards are idle, check if you're hogging too many.
~/.ssh/config, SSHs into all servers