Part One · Engineering
猫咪寄养
Web App
Web App
从零到生产,由 Claude Code 全程构建
 GitHub Copilot
GitHub Copilot Cursor
Cursor Gemini CLI
Gemini CLI Claude Code ✦
Claude Code ✦ OpenClaw
OpenClaw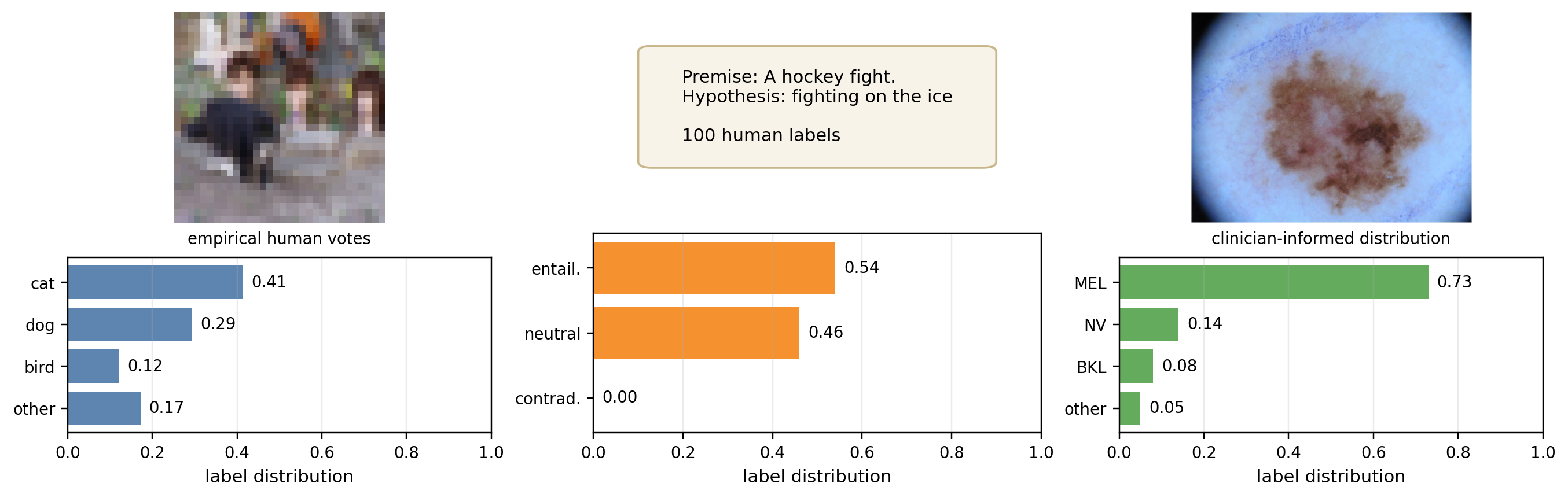
Conformal Prediction × 标注歧义
当 ground truth 本身模糊(多个 annotator 不同意),CP 的覆盖率保证还成立吗?
Calibration 在这个 setting 下根本没人做过
标注歧义 + calibration——连"该怎么评估"都没有定论
Pivot → CalibrationAGT
Calibration 在这个 setting 下同样值得系统研究。
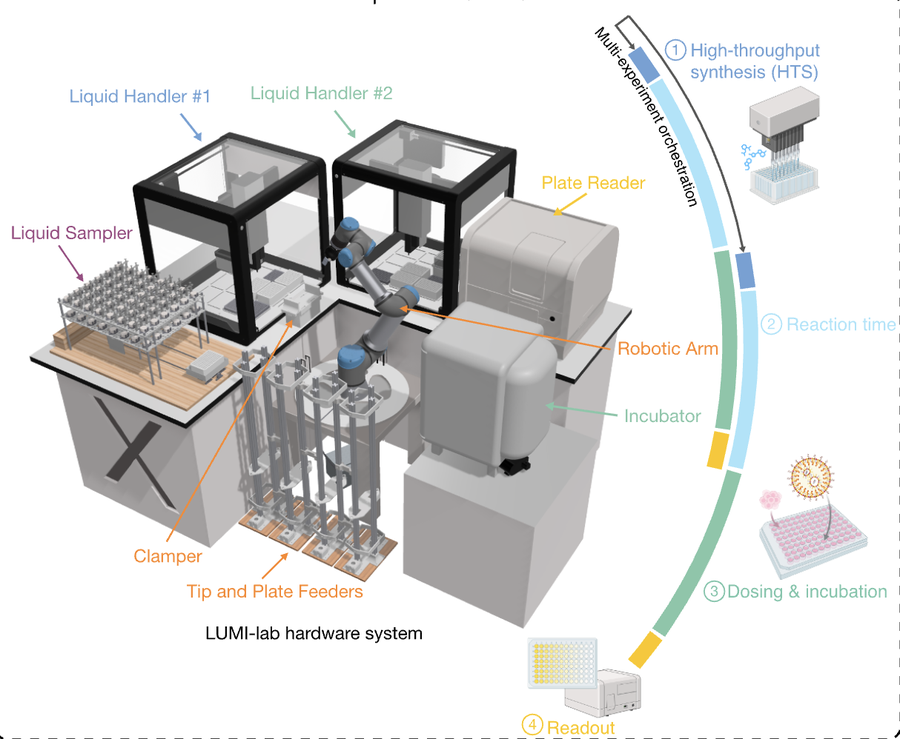
图1:LUMI-lab 系统总览——Foundation Model + 主动学习 + 机器人实验室 → 合成 1,700 个 LNP → 小鼠肺部基因编辑效率 20.3%
工作,是对结果负责
不是对过程负责,不是对代码行数负责,不是对"我自己写的"负责

"Vibe coding — fully give in to the vibes, embrace exponentials, and forget that the code even exists."
沉浸进去,拥抱指数级,忘掉代码本身的存在
X · Feb 2025 → now: "agentic engineering"

"We may see the first AI agents join the workforce and materially change the output of companies."
AI agent 将首次进入劳动力市场,实质性地改变企业产出
Blog · Jan 2025

"AI could soon compress decades of scientific progress into just a few years."
AI 或将把数十年的科学进步压缩进短短几年
Machines of Loving Grace · Oct 2024
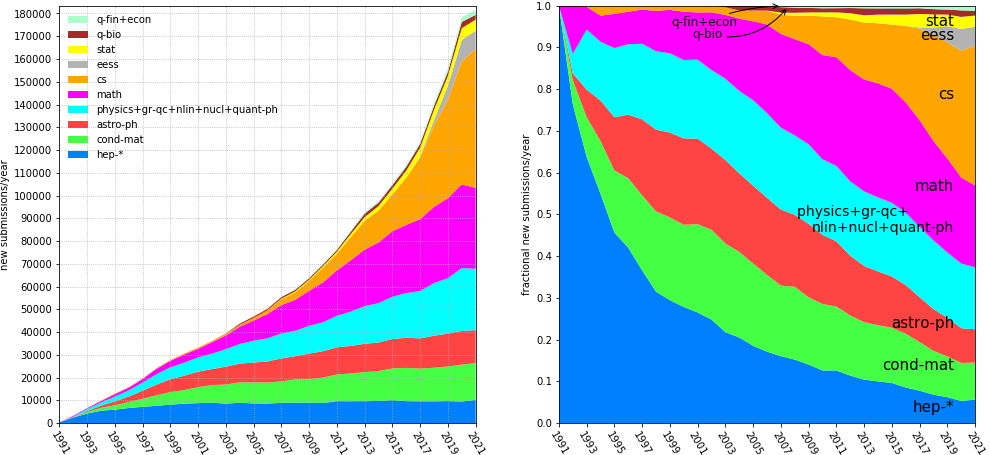
Agent 让人人都能快速产出论文——arxiv 每天几百篇,reviewers 已经看不过来了
arxiv 年提交量 · arxiv.org/stats(2025年已超 2.8万篇/月)
Stanford · Oct 2025 · agents4science.stanford.edu
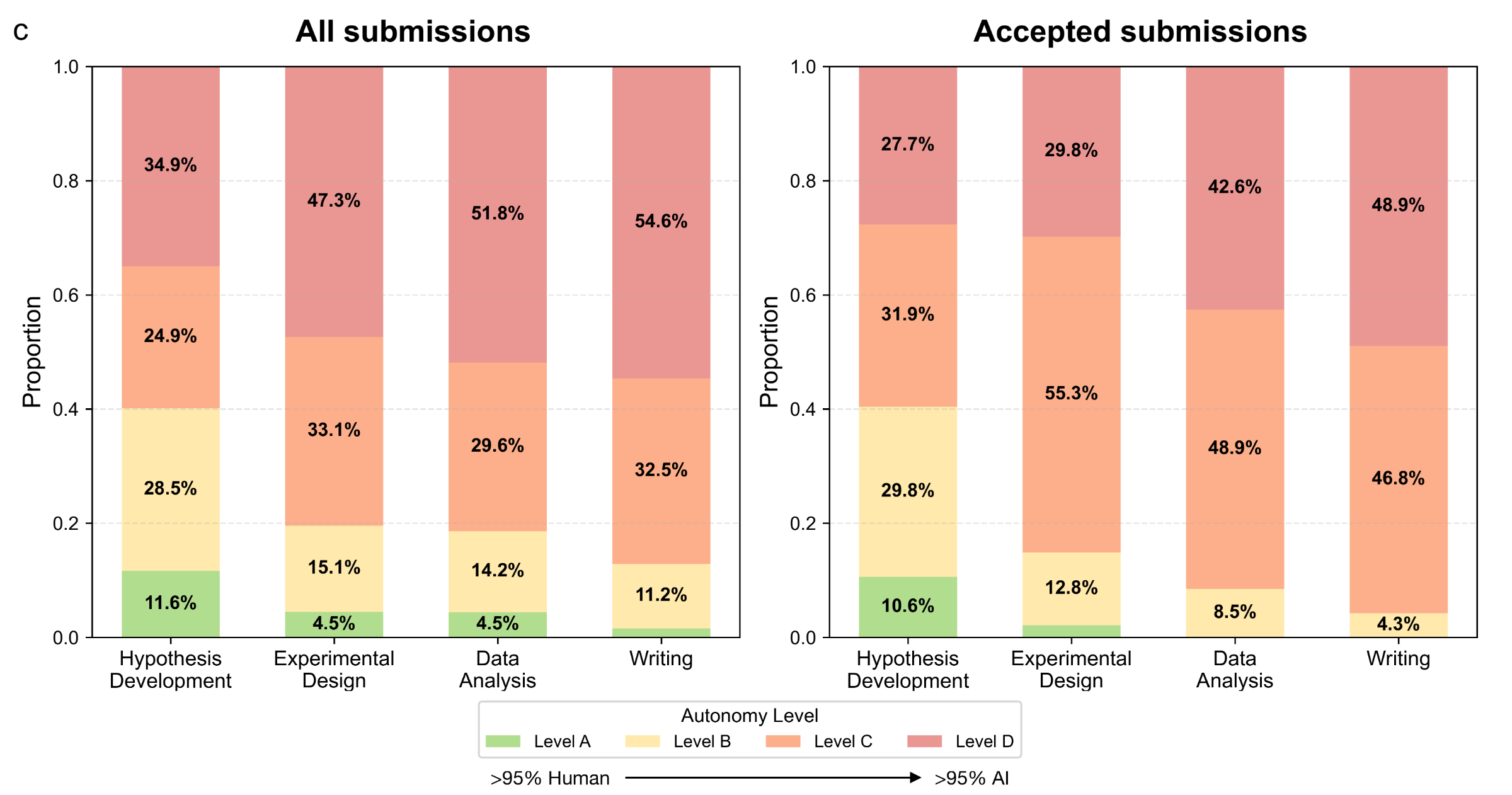
AI 能产出论文——但提出好问题仍然需要人
参考:李宏毅 AI Agent (3/3) · NTU 2026
Andrew Hall (Stanford) · 「100x Research Assistant」
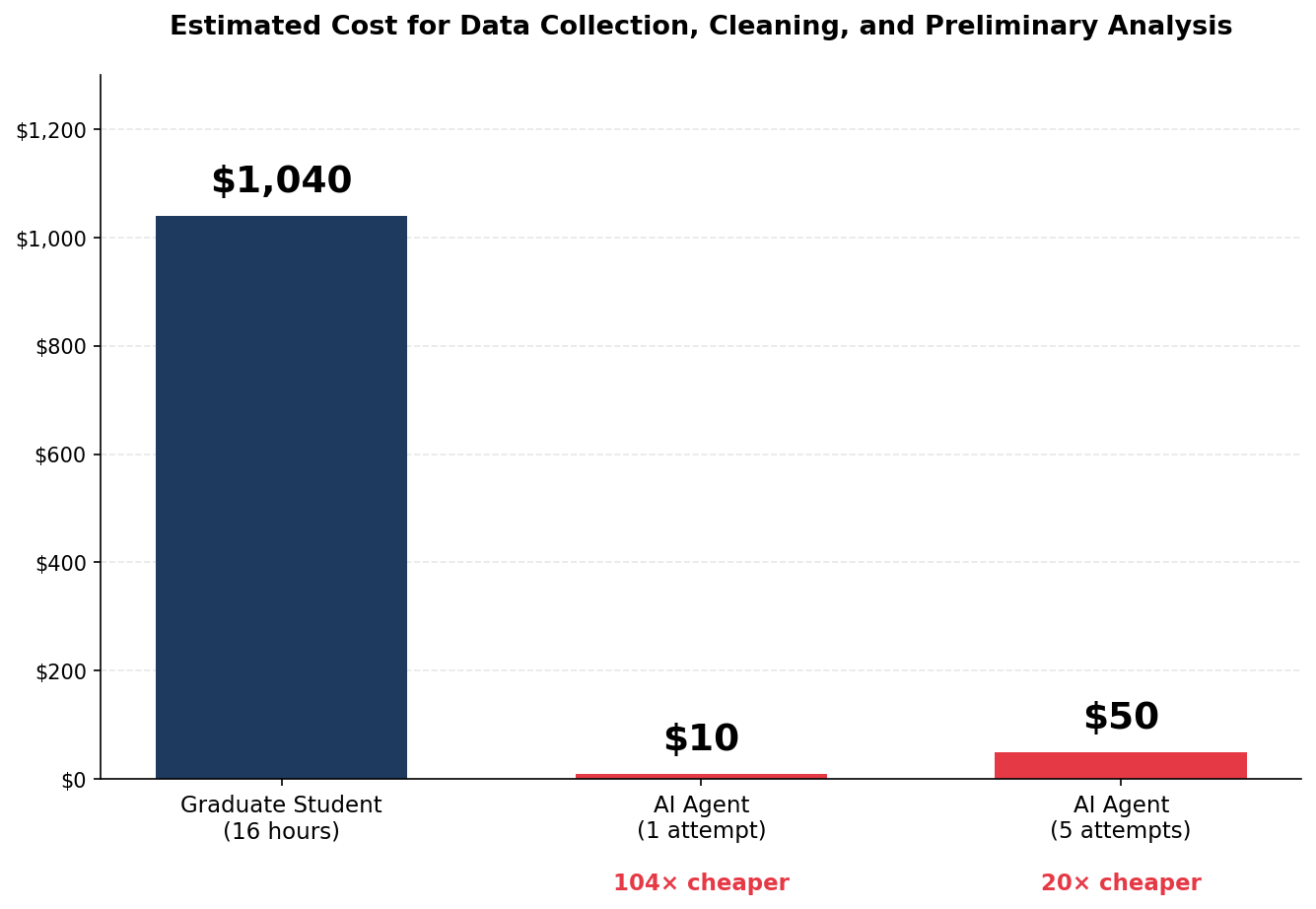
博士生:16h / $1,040 vs Claude Code:1h / $10(104× cheaper)
但:人类还没有被替代
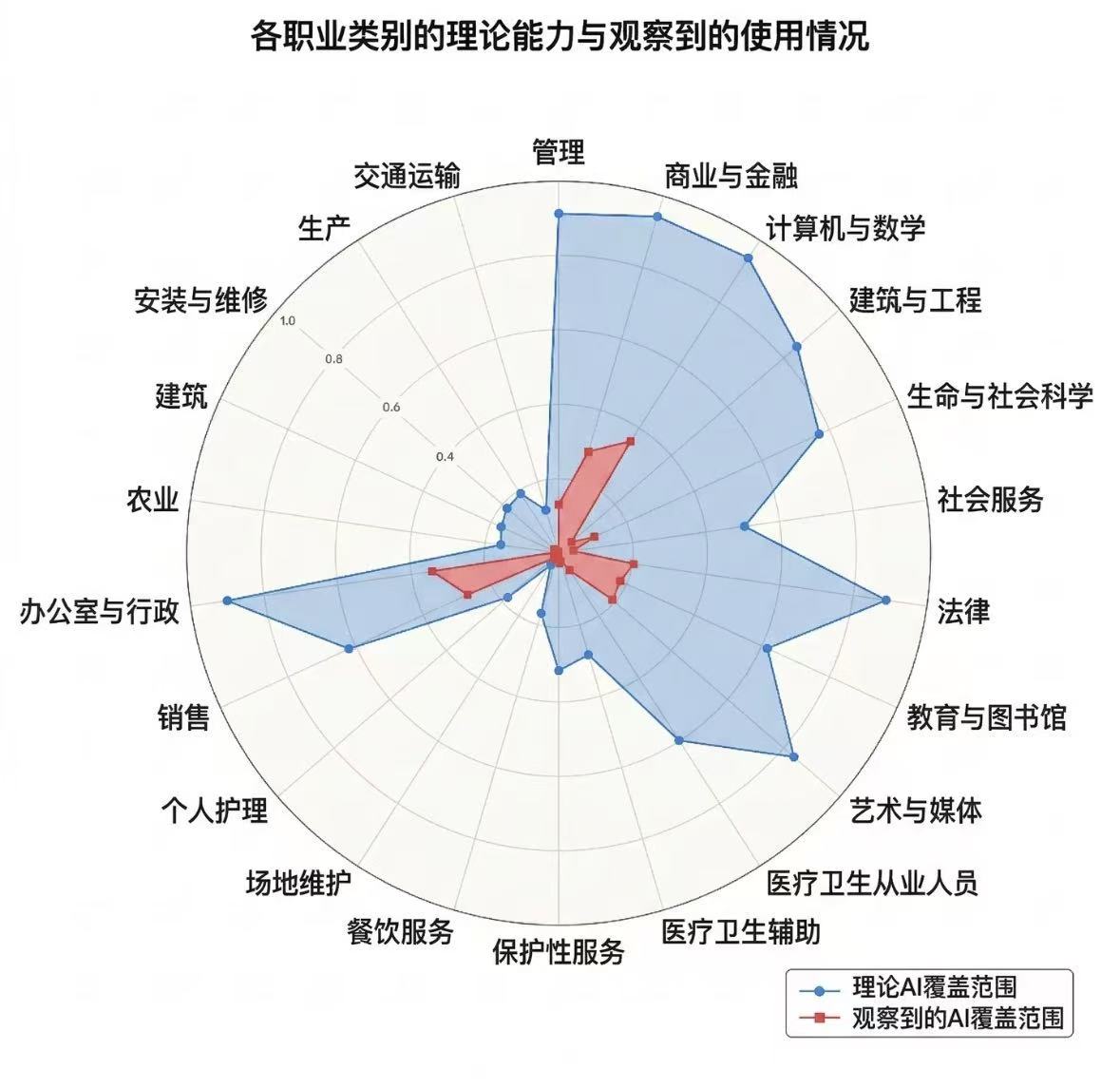
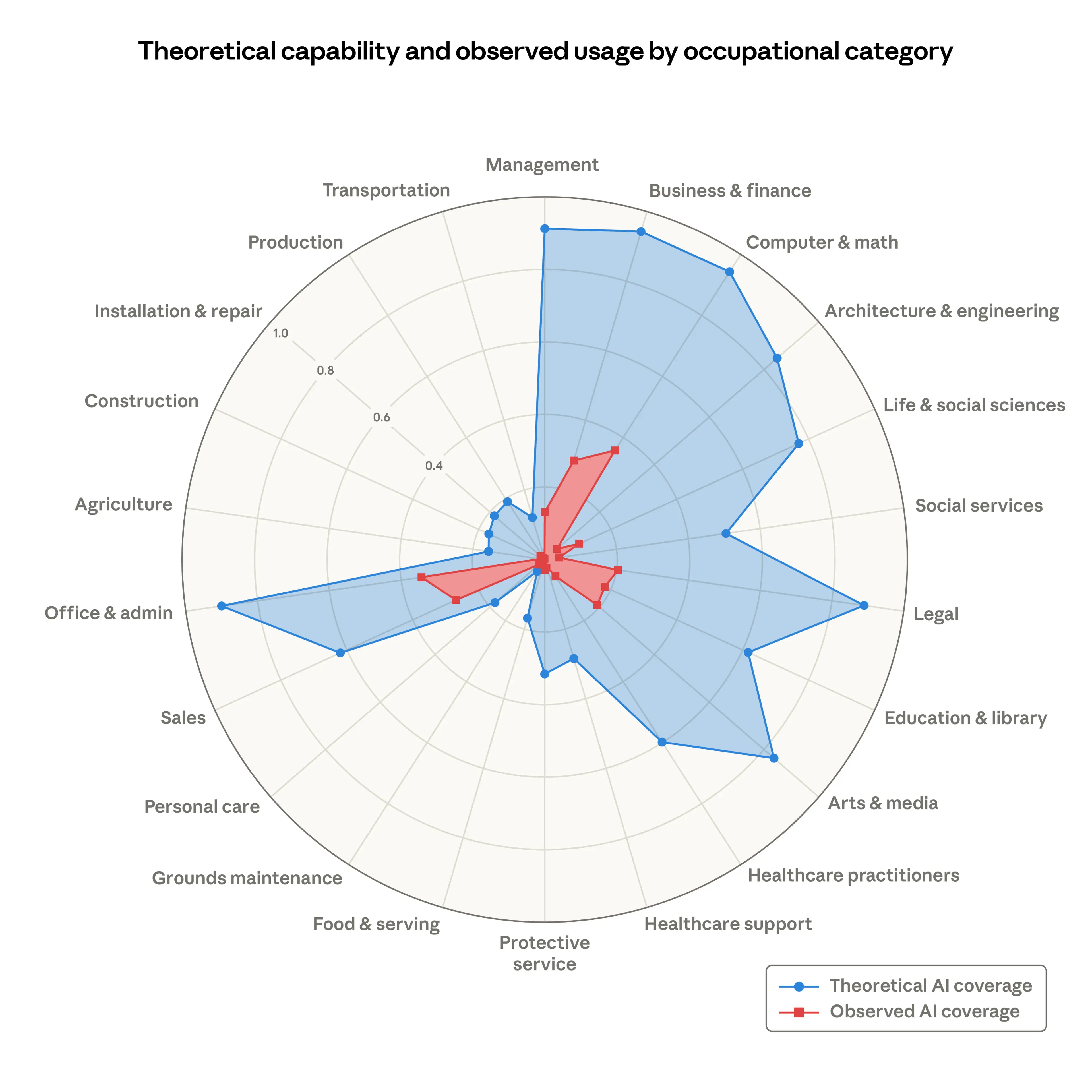
实时监控所有服务器的 GPU 状态——
看看有没有闲置的卡,也看看自己是不是用了太多卡。
~/.ssh/config,SSH 进所有服务器